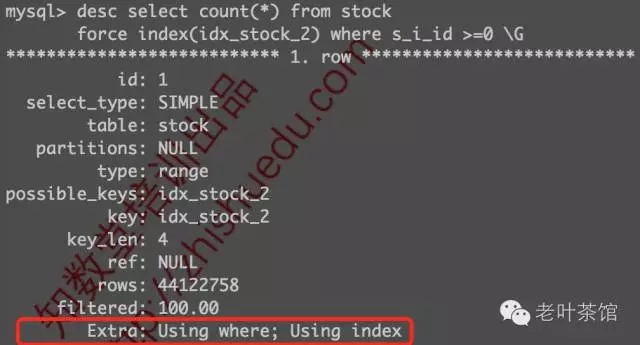
- InnoDB: SELECT COUNT(*) FROM t statements now invoke a single handler call to the storage engine to scan the clustered index and return the row count to the Optimizer. Previously, a row count was typically performed by traversing a smaller secondary index and invoking a handler call for each record. A single handler call to the storage engine to count rows in the clustered index generally improves SELECT COUNT(*) FROM t performance. However, in the case of a large clustered index and a significantly smaller secondary index, performance degradation is possible compared to performance using the previous, non-optimized implementation. For more information, see Limits on InnoDB Tables.
简单地说就是:COUNT(*)会选择聚集索引,进行一次内部handler函数调用,即可快速获得该表总数。我们可以通过执行计划看到这个变化,例如:
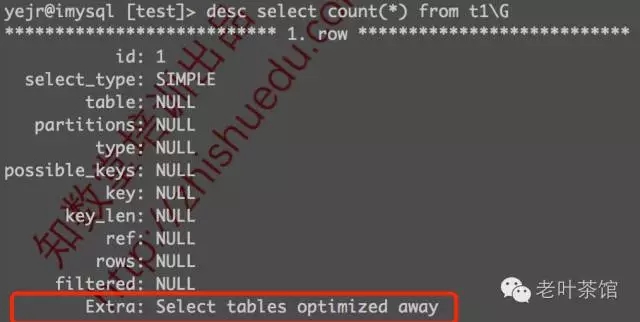
很明显,在查询优化器阶段就已经得到优化了,相比效率应该杠杠的吧,我们稍后再来对比看看。
补充说下,5.7以前的版本中,COUNT(*)请求通常是:扫描普通索引来获得这个总数。也来看看5.6下的执行计划是怎样的:
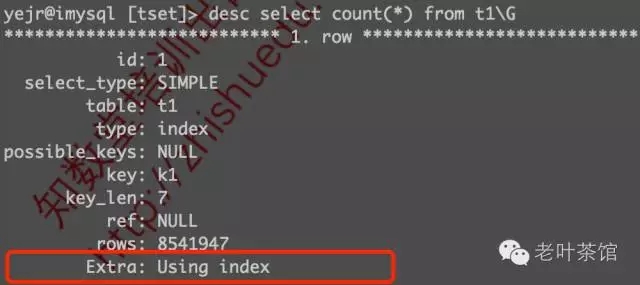
可以看到,可以利用覆盖索引来完成COUNT(*)请求。
|
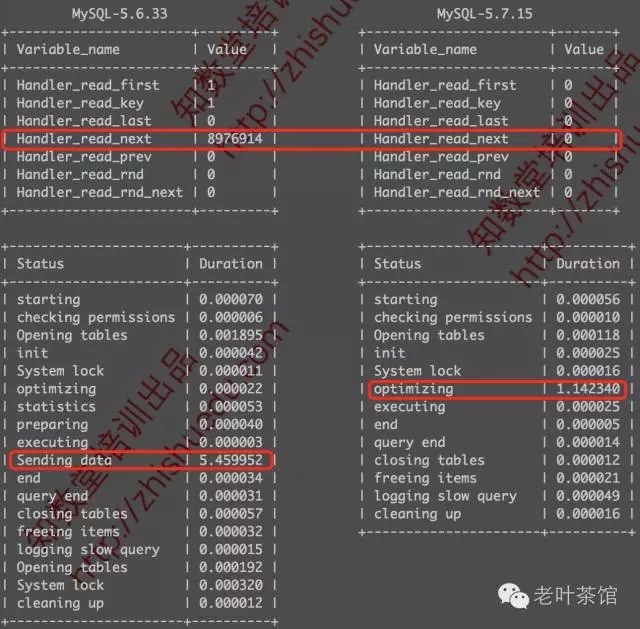
count(*)对比测试 |
MySQL 5.6.33 |
MySQL 5.7.15 |
相差 |
|
表数据量 |
8976914 |
9000270 |
100.26% |
|
耗时(秒) |
5.459952 |
1.142340 |
20.92% |
- InnoDB: SELECT COUNT(*) FROM t statements now invoke a single handler call to the storage engine to scan the clustered index and return the row count to the Optimizer. Previously, a row count was typically performed by traversing a smaller secondary index and invoking a handler call for each record. A single handler call to the storage engine to count rows in the clustered index generally improves SELECT COUNT(*) FROM t performance. However, in the case of a large clustered index and a significantly smaller secondary index, performance degradation is possible compared to performance using the previous, non-optimized implementation. For more information, see Limits on InnoDB Tables.
|
count(*)对比测试 |
MySQL 5.6.33 |
MySQL 5.7.15 |
相差 |
|
表数据量 |
1亿 |
1亿 |
0.00% |
|
耗时(秒) |
693.66 |
5331.69 |
768.63% |